The foolproof guide to using MTTR, MTBF and MTTF
Introduction to failure measurements
Before we get into the explanation of MTBF, MTTR and MTTF. It's important to know that asset performance metrics are critical for any organization whose operations depend on equipment. Only by tracking what is likely to fail can an organization maximize availability and minimize downtime.
Asset performance metrics are critical for any organization whose operations depend on equipment. Only by tracking what is likely to fail can an organization maximize availability and minimize downtime.
Tracking asset reliability is a challenge that engineering and maintenance managers face on a daily basis. While failure metrics can be very useful in this context, to use them effectively, you need to know what their acronyms mean, how to distinguish them, how to calculate them, and what it tells you about your assets.
Even the most efficient maintenance teams experience equipment breakdowns. That's why it's essential to plan for them.
But first, what does equipment failure look like?
Failure exists in varying degrees (e.g., partial or total failure), but in the most basic terms; a failure simply means that a system; component or device can no longer produce the specific results desired. Even if a piece of manufacturing equipment is still running and producing items; it has failed if it does not deliver the expected quantities.
Proper management of failure can help you significantly reduce its negative impact. To help you effectively manage failure; there are a number of critical metrics that should be monitored. Understanding these metrics will eliminate guesswork and give maintenance managers the hard data they need to make informed decisions.
What are the failure indicators that need to be tracked?
Across all industries and applications, we've found that these are MTTR, MTBF and MTTF. We will discuss what each of these acronyms mean and how you can use them to improve your operations.
The importance of reliable data
But before we do, we need to discuss something that is often overlooked: the importance of having reliable data behind your failure indicators.
In order to make data-driven improvements in the event of equipment failure, it is crucial that the right data is collected and that the data is accurate.
High-level failure statistics require a significant amount of meaningful data. As we will show in the maintenance indicator calculations below; the following inputs should be collected as part of your maintenance history:
- Hours spent on maintenance
- Number of failures
- Operating time
As tedious as recording maintenance numbers can be; it's an essential part of improving operations. This process can be time-consuming when done manually, but it's simplified with a CMMS or through Industry 4.0. which allows you to quickly and easily record reliable data for work hours and downtime on your phone or a dedicated screen while performing maintenance tasks.
Thus, inaccurate data collection can lead to many problems. Maintenance technicians who may sometimes write down the wrong number is just one example. A potentially much bigger problem is neglecting to record tasks, which leads to incomplete data.
If data is missing or inaccurate, your failure metrics will be useless in informing decisions about improving operations. Worse yet, if you don't know that the data is unreliable, you could end up making operational decisions that could actually be counterproductive and harmful.
Now that we've got that out of the way, let's focus on the things you really came here for.
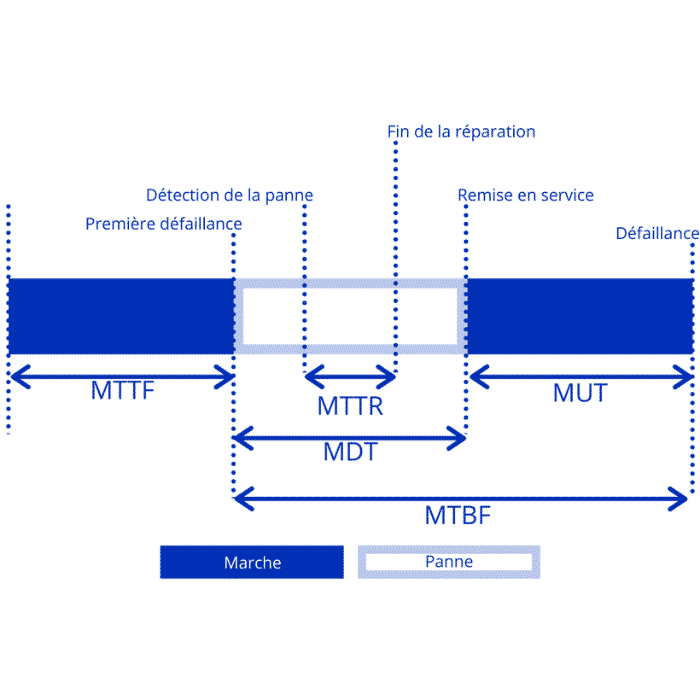
Definition of MTTR mean time to repair
Mean Time To Repair (MTTR) refers to the time it takes to repair a system and restore it to full functionality.
The MTTR clock begins flashing at the start of repairs and continues until operations are restored. This includes the repair time, test period and return to normal operation.
Calculation of the mean time to repair MTTR
To calculate the MTTR, divide the total maintenance time by the total number of maintenance actions in a given period.
Imagine a pump that breaks down three times in one work day. The time spent repairing each of these failures totals one hour. In this case, the MTTR would be 1 hour / 3 = 20 minutes.
A few points to note:
Generally, each instance of failure varies in severity. So, while some incidents take days to fix, others may take only minutes. Therefore, the MTTR gives an average of what to expect.
To achieve reliable results, it is important that each repair be performed by competent and trained personnel who can follow well-defined procedures.
Every effective maintenance system should always seek to reduce the MTTR as much as possible. This can be done in several ways.
One approach is to track spare parts and inventory levels (thus saving downtime in parts procurement).
Another way is to implement proactive maintenance strategies such as predictive maintenance. Predictive maintenance (PdM) will allow you to better monitor the condition of equipment in service and more accurately predict potential failures by using condition monitoring sensors mounted directly on components that are likely to fail.
These sensors can alert you well in advance when a breakdown is to be expected. At this point, the repair is no longer reactive but predictive; because the maintenance manager has enough time to organize all the resources needed to get the job done.
Why is the MTTR useful?
Taking too long to repair a system or equipment is not desirable; it can have a very negative impact on business results. This is especially true for processes that are particularly sensitive to failure. This often results in production downtime; missed deadlines; lost revenue, etc.
Understanding and understanding the MTTR correctly is an important tool for any organization; as it tells you how effectively you can respond and repair any problems with your assets. Most organizations seek to reduce MTTR with an in-house maintenance team supported by the necessary resources; tools; spare parts and CMMS software.
Maintenance managers can use MTTR to inform maintenance decisions such as:
- When to repair or replace assets
- Quantity of parts and inventory to have on hand
- If you need to rent or buy equipment
Average repair time vs. average recovery time
There are several commonly used terms for the acronym "MTTR". The two most common are "mean time to repair" (described above) and "mean time to recover".
Mean Time to Recovery is a measure of the time from when the failure is first discovered to when the equipment returns to operation. Thus; in addition to the time to repair; the time to test and return to a normal operating state; it captures the time to report failures and diagnosis.
Although the two terms are often used interchangeably, the need for distinction becomes important in the context of service level agreements and maintenance contracts.
Therefore, all parties in such contracts will have to agree on what exactly they are measuring.
Definition of the mean time between failures MTBF
Definition of the mean time between failures MTBF
The second failure indicator we will address is the mean time between failures. MTBF measures the expected time between a previous failure of a mechanical/electrical system and the next failure in normal operation. In simpler terms; MTBF helps you predict how long an asset can operate before the next unplanned failure.
The expectation that a failure will occur at some point is an essential part of MTBF.
Although the term MTBF is used for repairable systems; but it does not take into account units that are down for routine scheduled maintenance (recalibration; servicing; lubrication) or preventive replacement of spare parts. Instead, it captures failures that occur due to design conditions that require the unit to be taken out of service before it can be repaired.
So while MTTR measures availability; MTBF measures availability and reliability. The higher the MTBF number, the longer the system is likely to operate before it fails.
Calculation of the mean time between failures MTBF
Expressed mathematically, the time lapses from one failure to the next can be calculated using the sum of the uptime divided by the number of failures.
Looking at the example of the pump we mentioned under MTTR, out of the expected run time of ten hours, it ran for nine hours and was down for one hour, spread over three times. Therefore, MTBF = 9 hours / 3 = 3 hours.
As you can see in the example above, repair time is not included in the MTBF calculation.
In addition to the design conditions mentioned above, other common factors tend to influence the MTBF of systems in the field.
One of the main factors is human intervention. For example; a low MTBF could indicate poor handling of the asset by its operators or poorly executed repair work in the past.
Why is the MTBF useful?
MTBF is an important marker of reliability engineering and has its roots in the aviation industry, where an aircraft failure can result in death.
For critical assets such as aircraft, safety equipment and generators, MTBF is an important indicator of expected performance. Therefore, manufacturers use it as a quantifiable reliability measure and as an essential tool in the design and production stages of many products. It is commonly used today in mechanical and electronic system design; safe plant operation; product procurement, etc.
Even everyday decisions such as buying a particular brand of car or computer are affected by the buyer's desire for a product with a higher MTBF than what the next brand has to offer.
Although MTBF does not consider planned maintenance; it can still be applied for things like calculating inspection frequency for preventive replacements.
While it is known that an asset will likely operate for a number of hours before the next failure, introducing preventive actions such as lubrication or recalibration can help keep that failure to a minimum and extend the asset's operating life.
What is the mean time to failure MTTF?
Mean Time To Failure (MTTF) is a very basic measure of reliability used for non-repairable systems. It represents the expected duration of operation of a component until it fails.
MTTF is what we commonly refer to as the lifetime of any product or device. Its value is calculated by looking at a large number of items of the same type over an extended period of time and seeing what their mean time to failure is.
In the manufacturing industry; MTTF is one of many measures commonly used to assess the reliability of manufactured products. However; there is still a lot of confusion in differentiating between MTTF and MTBF as they are both somewhat similar in definition. The good news is that this is easily resolved by remembering that while MTBF is only used to refer to repairable items; MTTF is used to refer to non-repairable items.
When using MTTF as a failure measure, repairing the asset is not an option.
How do you calculate the MTTF?
MTTF is calculated as the total number of hours of operation, divided by the total number of items tracked.
Suppose we tested three identical pumps until they all failed. The first pump system failed after eight hours, the second at ten hours, and the third at twelve hours. In this case, the MTTF would be
(8 + 10 + 12) / 3 = 10 hours.
This leads us to conclude that this particular type and model of pump will need to be replaced, on average, every 10 hours.
The only surefire way to increase MTTF is to look for better quality items made from more durable materials.
Why is the MTTF useful?
MTTF is an important indicator used to estimate the life of products that are not repairable. Common examples of these products range from items such as fan belts in automobiles to light bulbs in our homes and offices.
MTTF is important especially for reliability engineers when they need to estimate the life of a component as part of a larger piece of equipment. This is especially true when the entire business process is sensitive to the failure of the equipment in question.
In such cases, MTTF becomes the primary indicator of equipment reliability; with the intent of maximizing asset life. A shorter MTTF means more frequent downtime and interruptions.
Final thoughts
One of the top priorities for maintenance managers is to ensure maximum operational availability of their equipment; as well as to ensure safe and efficient equipment operations. Understanding the calculations and use of failure indicators will allow maintenance professionals to more accurately determine when a critical asset is most likely to fail.
Based on their findings, they can develop better asset management strategies and improve their overall maintenance processes.
By calculating failure indicators and planning maintenance based on these results; they can also reduce their organization's reliance on reactive maintenance in favor of planned (predictive) maintenance; which may be exactly what they need to drive business growth.
The essential guide to efficiently managing a production line

Follow our thoughts on social networks


