Machine learning for predictive maintenance: where to start?
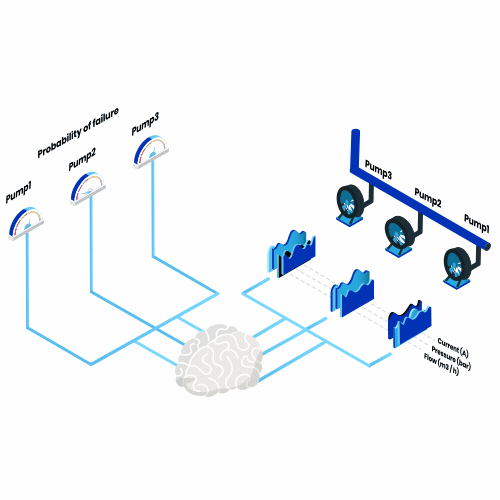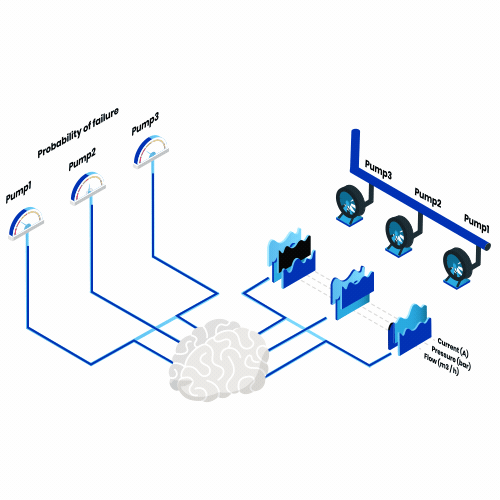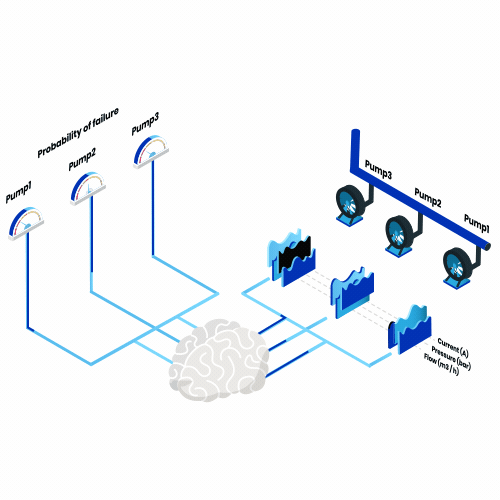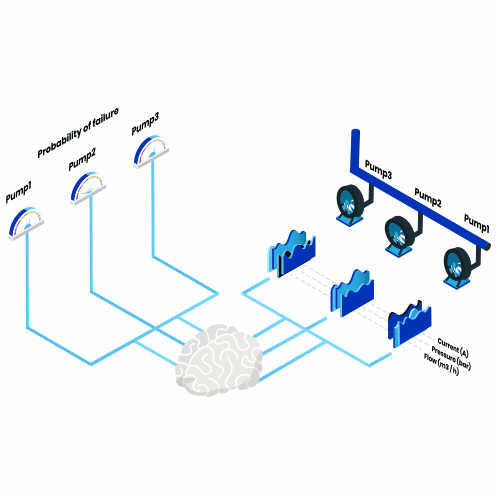
What is predictive maintenance? Think of all the machines you use in a year, everything from a toaster every morning to a plane every summer vacation. Now imagine that, from now on, one of them would break down every day. What impact would that have?
We are surrounded by machines that make our lives easier, but we are also increasingly dependent on them. Therefore, the quality of a machine depends not only on its usefulness and efficiency, but also on its reliability. And with reliability comes maintenance.
When the impact of a failure cannot be tolerated, such as a faulty aircraft engine for example, the machine is subjected to preventive maintenance, which involves periodic inspection and repair; often scheduled according to the time of service.
So, the objective of predictive maintenance is to answer this question. Thus, we seek to build models that quantify the risk of machine failure at any point in time and use this information to improve maintenance planning.
The success of predictive maintenance models depends on three main elements: having the right data, defining the problem appropriately and evaluating the predictions correctly.
In this article, we will expand on the first two points and provide information on how to choose the modeling technique that best fits the question you are trying to answer and the data you have.
DATA COLLECTION
First, to create a failure model, we need sufficient historical data to capture information about the events leading to a failure.
In addition to this, valuable information comes from the general "static" characteristics of the system; such as mechanical properties, average usage and operating conditions. However, more data is not always better. When collecting data and supporting a failure model, it is important to take an inventory of the following:
What does the "failure process" look like? Is it a slow or acute degradation process?
What parts of the machine/system could be related to each type of failure? What can be measured on each that reflects their condition? How often and how accurately should these measurements be made?
For example, the life of the machines is usually in the order of a few years; this means that data must be collected for an extended period of time in order to observe the system throughout its degradation process.
In an ideal scenario, the data scientist would be involved in the data collection plan to ensure that the data collected is suitable for the model to be built. However, what most often happens in real life is that the data has already been collected before the data scientist arrives and he/she has to try to make the most of what is available.
So, depending on the characteristics of the system and the available data, a good framing of the model to be built is essential: what question do we want the model to answer and is it possible with the data we have?
THE DEFINITION OF THE PROBLEM
When thinking about how to define a predictive maintenance model, it is important to keep a few questions in mind:
- What type of output should the model give?
- Is there enough historical data available or just static data?
- Is each recorded event labeled; i.e., which measurements correspond to a good operation and which correspond to a failure? Or at least, is it known when each machine failed (or not at all)?
- When labeled events are available; what is the proportion of the number of events of each type of failure and good events?
- How far in advance should the model be able to indicate that a failure will occur?
- What are the performance objectives for which the model should be optimized? What is the consequence of not predicting a failure?
So, with all this information at hand, we can now decide which modeling strategy best fits the available data and the desired output; or at least which one is the best candidate to begin with. There are several modeling strategies for predictive maintenance and we will describe four of them based on the question they aim to answer and the type of data they require:
- Regression models for predicting remaining useful life (RUL)
- Classification models to predict failures in a given time window
- Report abnormal behavior
- Survival models for predicting the probability of failure over time
STRATEGY 1 PREDICTIVE MAINTENANCE:
Regression models to predict remaining useful life.
OUTPUT: How many days / cycles are left before the system fails?
DATA FEATURES: Static and historical data are available, and each event is labeled. Multiple events of each failure type are present in the dataset.
ASSUMPTIONS / BASIC REQUIREMENTS:
Based on the static characteristics of the system and its current behavior; the remaining useful time can be predicted, which implies that static and historical data are needed and that the degradation process is regular.
Only one type of "path to failure" is modeled: if several types of failure are possible and the behavior of the system preceding each of them differs; a dedicated model must be created for each of them.
Labeled data are available and measurements have been taken at various times during the life of the system.
STRATEGY 2 PREDICTIVE MAINTENANCE:
Classification models for predicting failure in a given time window
Creating a model that can predict lifetimes very accurately can be very difficult.
In practice, however, it is usually not necessary to predict the service life accurately. Often, the maintenance team only needs to know if the machine will break down soon. This leads to the following strategy:
QUESTION: Will a machine fail in the next N days/cycles?
DATA CHARACTERISTICS: Same as Strategy 1
ASSUMPTIONS / BASIC REQUIREMENTS: The assumptions of a classification model are very similar to those of regression models. They differ mainly on the following bridges:
- Since we define a failure in a time window instead of an exact time; the requirement of regularity of the degradation process is relaxed.
- Classification models can handle several types of failure, provided they are presented as a multi-class problem, for example: class = 0 corresponding to no failure in the next n days, class = 1 for type 1 failure in the next n days, class = 2 for a severe failure in the next n days and so on.
- Labeled data is available and there are "enough" cases of each type of failure to train and evaluate the model.
In general, regression and classification models model the relationship between the characteristics and the degradation path of the system. This means that if the model is applied to a system that has a different failure type not present in the training data, the model will fail to predict it.
STRATEGY 3 PREDICTIVE MAINTENANCE:
Report abnormal behavior
Both of the above strategies require many examples of both normal behavior (of which we often have many) and examples of failures.
However, how many planes will you let crash to collect data? If you have critical systems, in which acute repairs are difficult; there are often only limited, if any, examples of failures. In this case, a different strategy is needed:
QUESTION: Is the behavior displayed normal?
DATA CHARACTERISTICS: Static and historical data are available, but either the labels are unknown; or too few failure events have been observed or there are too many failure types
BASIC HYPOTHESES / REQUIREMENTS: It is possible to define what normal behavior is and the difference between actual behavior and "normal" behavior is related to degradation leading to failure.
The generality of an anomaly detection model is both its greatest advantage and its greatest pitfall: the model should be able to report all types of failure; even if it has no prior knowledge of them. However, abnormal behavior does not necessarily lead to a failure. And if it does, the model does not give any information on how long it should occur.
Evaluating a fault detection model is also difficult due to the lack of labeled data. If at least some labeled fault data is available, it can and should be used to evaluate the algorithm. When no labeled data is available, the model is usually made available and domain experts provide feedback on the quality of its anomaly reporting capability.
STRATEGY 4 PREDICTIVE MAINTENANCE:
Survival models for predicting the probability of failure over time
The previous three approaches focus on prediction, giving you enough information to apply maintenance before failure. If, however, you are interested in the degradation process itself and the resulting probability of failure, the latter strategy is best suited for you.
QUESTION: Given a set of characteristics, how does the risk of default change over time?
DATA CHARACTERISTICS: Static data available, information on the reported time of failure of each machine or recorded date when a given machine became unobservable in the event of failure.
A survival model estimates the probability of failure for a given type of machine as a function of static characteristics and is also useful for analyzing the impact of certain characteristics on service life. It therefore provides estimates for a group of machines with similar characteristics. Therefore, for a specific machine under study, it does not take into account its specific current state.
TO CONCLUDE
What is the most appropriate approach for a predictive maintenance model? As with all other data science problems, nothing is won on the first try! The advice here is to start by understanding the types of failures you are trying to model, the type of output you want the model to deliver, and the type of data available.
After putting it all together with the tips given above, I hope you now know where to start!
Need an expert opinion?
Follow our innovations on social networks
We frequently publish on social networks (Linkedin, Twitter and Medium) our innovations and the new functionalities of our industrial management solutions.
Also, we would be happy to share with you the latest trends in industrial management 4.0 through high quality content that you could share with others.


