Aprendizaje automático para el mantenimiento predictivo: ¿por dónde empezar?
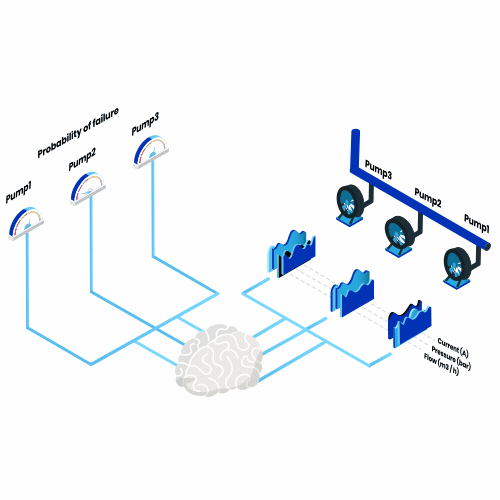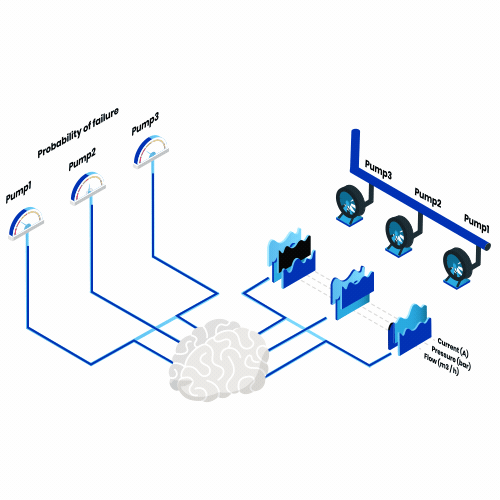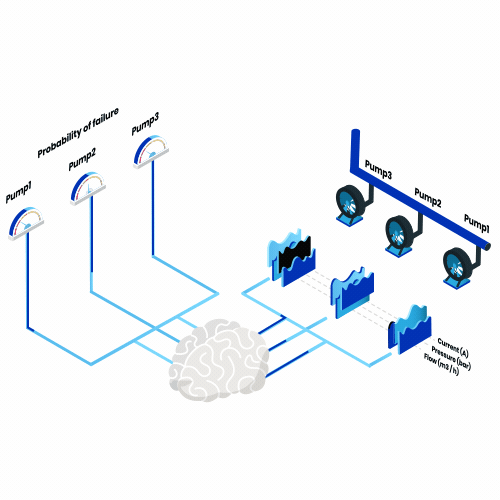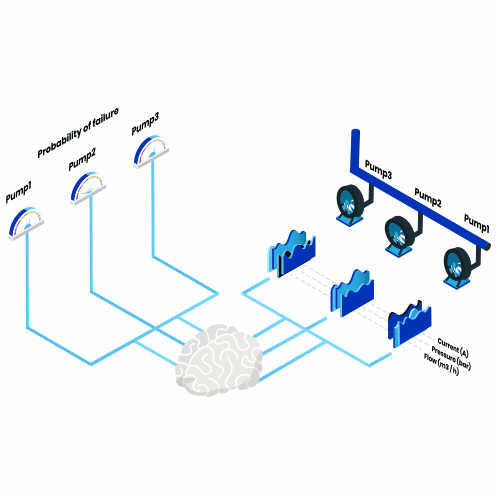
¿Qué es el mantenimiento predictivo? Piense en todas las máquinas que utiliza a lo largo de un año, desde una tostadora cada mañana hasta un avión cada verano. Ahora imagina que, a partir de ahora, una de ellas se estropeara todos los días. ¿Qué consecuencias tendría?
Estamos rodeados de máquinas que nos facilitan la vida, pero también dependemos cada vez más de ellas. Por eso, la calidad de una máquina no sólo depende de su utilidad y eficacia, sino también de su fiabilidad. Y con la fiabilidad viene el mantenimiento.
Cuando no se puede tolerar el impacto de una avería, como un motor de avión defectuoso, por ejemplo, la máquina se somete a un mantenimiento preventivo, que implica inspecciones y reparaciones periódicas, a menudo programadas en función del tiempo de funcionamiento.
El objetivo del mantenimiento predictivo es responder a esta pregunta. Queremos crear modelos que cuantifiquen el riesgo de avería de una máquina en cualquier momento y utilizar esta información para mejorar la planificación del mantenimiento.
El éxito de los modelos de mantenimiento predictivo depende de tres elementos principales: disponer de los datos adecuados, definir correctamente el problema y evaluar correctamente las predicciones.
En este artículo, ampliaremos los dos primeros puntos y proporcionaremos información sobre cómo elegir la técnica de modelización que mejor se adapte a la pregunta que intenta responder y a los datos de que dispone.
RECOGIDA DE DATOS
En primer lugar, para crear un modelo de fallo, necesitamos suficientes datos históricos que recojan información sobre los acontecimientos que conducen al fallo.
Además, las características "estáticas" generales del sistema, como las propiedades mecánicas, el uso medio y las condiciones de funcionamiento, aportan información valiosa. Sin embargo, más datos no siempre es mejor. A la hora de recopilar datos y respaldar un modelo de fallos, es importante hacer un inventario de los siguientes elementos:
¿Cómo es el "proceso de descomposición"? ¿Es un proceso de degradación lenta o aguda?
¿Qué partes de la máquina/sistema podrían estar relacionadas con cada tipo de avería? ¿Qué se puede medir en cada una de ellas que refleje su estado? ¿Con qué frecuencia y precisión deben realizarse estas mediciones?
Por ejemplo, la vida útil de las máquinas suele ser del orden de unos pocos años, lo que significa que es necesario recopilar datos durante un periodo prolongado para observar el sistema a lo largo de su proceso de degradación.
En un escenario ideal, el científico de datos participaría en el plan de recogida de datos para asegurarse de que los datos recogidos son adecuados para el modelo que se va a construir. Sin embargo, lo que suele ocurrir en la vida real es que los datos ya se han recogido antes de que llegue el científico de datos y éste debe intentar sacar el máximo partido de lo que hay disponible.
Así pues, en función de las características del sistema y de los datos disponibles, es esencial disponer de un buen marco para la construcción del modelo: ¿qué pregunta queremos que responda el modelo y es esto posible con los datos de que disponemos?
DEFINICIÓN DEL PROBLEMA
Al pensar en cómo definir un modelo de mantenimiento predictivo, es importante tener en cuenta algunas cuestiones:
- ¿Qué tipo de resultados debe dar el modelo?
- ¿Hay suficientes datos históricos disponibles o sólo datos estáticos?
- ¿Está etiquetado cada evento registrado, es decir, qué mediciones corresponden a un buen funcionamiento y cuáles a un fallo? O, al menos, ¿se sabe cuándo ha fallado (o no ha fallado) cada máquina?
- Cuando se dispone de sucesos etiquetados, ¿cuál es la proporción del número de sucesos de cada tipo de fallo y de sucesos en buen estado de funcionamiento?
- ¿Con cuánta antelación debe poder indicar el modelo que se va a producir un fallo?
- ¿Cuáles son los objetivos de rendimiento para los que debe optimizarse el modelo? ¿Cuál es la consecuencia de no predecir un fallo?
Así que, con toda esta información a mano, ya podemos decidir qué estrategia de modelización se ajusta mejor a los datos disponibles y al resultado deseado; o al menos cuál es la mejor candidata para empezar. Existen varias estrategias de modelización para el mantenimiento predictivo y vamos a describir cuatro de ellas en función de la pregunta a la que pretenden dar respuesta y el tipo de datos que requieren:
- Modelos de regresión para predecir la vida útil restante (RUL)
- Modelos de clasificación para predecir fallos dentro de una ventana temporal determinada
- Notificación de comportamientos anómalos
- Modelos de supervivencia para predecir la probabilidad de fallo a lo largo del tiempo
ESTRATEGIA 1 MANTENIMIENTO PREDICTIVO:
Modelos de regresión para predecir la vida útil restante.
SALIDA: ¿Cuántos días / ciclos quedan antes de que falle el sistema?
CARACTERÍSTICAS DE LOS DATOS: Se dispone de datos estáticos e históricos, y cada suceso está etiquetado. El conjunto de datos contiene varios sucesos de cada tipo de fallo.
SUPUESTOS / REQUISITOS BÁSICOS:
A partir de las características estáticas del sistema y de su comportamiento actual, se puede predecir el tiempo útil restante, lo que implica que se necesitan datos estáticos e históricos y que el proceso de degradación es regular.
Sólo se modela un tipo de "camino al fallo": si son posibles varios tipos de fallo y el comportamiento del sistema que precede a cada uno de ellos difiere, debe crearse un modelo específico para cada uno de ellos.
Se dispone de datos etiquetados y se han realizado mediciones en varios momentos de la vida útil del sistema.
ESTRATEGIA 2 MANTENIMIENTO PREDICTIVO:
Modelos de clasificación para predecir fallos en una ventana temporal determinada
Crear un modelo capaz de predecir la vida útil con gran exactitud puede ser muy difícil.
En la práctica, sin embargo, no suele ser necesario predecir con exactitud la vida útil. A menudo, el equipo de mantenimiento sólo necesita saber si la máquina se averiará pronto. Esto nos lleva a la siguiente estrategia:
PREGUNTA: ¿Se averiará una máquina en los próximos N días / ciclos?
CARACTERÍSTICAS DE LOS DATOS: Las mismas que para la estrategia 1
SUPUESTOS / REQUISITOS BÁSICOS: Los supuestos de un modelo de clasificación son muy similares a los de los modelos de regresión. Se diferencian principalmente en los siguientes aspectos:
- Dado que definimos un fallo en una ventana temporal en lugar de en un momento exacto, se relaja el requisito de que el proceso de degradación sea regular.
- Los modelos de clasificación pueden tratar varios tipos de fallo, siempre que se presenten como un problema multiclase, por ejemplo: clase = 0 correspondiente a ningún fallo en los próximos n días, clase = 1 para un fallo de tipo 1 en los próximos n días, clase = 2 para un fallo grave en los próximos n días, etc.
- Se dispone de datos etiquetados y hay "suficientes" casos de cada tipo de fallo para entrenar y evaluar el modelo.
En general, los modelos de regresión y clasificación modelan la relación entre las características y la trayectoria de degradación del sistema. Esto significa que si el modelo se aplica a un sistema con un tipo de fallo diferente no presente en los datos de entrenamiento, el modelo fallará en su predicción.
ESTRATEGIA 3 MANTENIMIENTO PREDICTIVO:
Notificación de comportamientos anómalos
Las dos estrategias anteriores requieren numerosos ejemplos tanto de comportamientos normales (de los que solemos tener muchos) como de ejemplos de fracasos.
Sin embargo, ¿cuántos aviones va a dejar que se estrellen para recoger datos? Si se trata de sistemas de misión crítica, en los que las reparaciones agudas son difíciles, los ejemplos de fallos suelen ser limitados, por no decir inexistentes. En este caso, se necesita una estrategia diferente:
PREGUNTA: ¿Es normal el comportamiento mostrado?
CARACTERÍSTICAS DE LOS DATOS: Se dispone de datos estáticos e históricos, pero o bien se desconocen las etiquetas; o bien se han observado muy pocos sucesos de fallo o hay demasiados tipos de fallo.
SUPUESTOS BÁSICOS / REQUISITOS: Es posible definir cuál es el comportamiento normal y la diferencia entre el comportamiento actual y el comportamiento "normal" está vinculada a la degradación que conduce al fallo.
La generalidad de un modelo de detección de anomalías es a la vez su mayor ventaja y su mayor escollo: el modelo debe ser capaz de señalar todos los tipos de fallos, aunque no tenga conocimiento previo de ellos. Sin embargo, un comportamiento anómalo no conduce necesariamente a un fallo. Y si lo hace, el modelo no da ninguna información sobre su duración.
La evaluación de un modelo de detección de fallos también es difícil debido a la falta de datos etiquetados. Si se dispone al menos de algunos datos etiquetados sobre fallos, pueden y deben utilizarse para evaluar el algoritmo. Cuando no se dispone de datos etiquetados, el modelo se suele poner a disposición de los expertos en la materia, que proporcionan información sobre la calidad de su capacidad de detección de fallos.
ESTRATEGIA 4 MANTENIMIENTO PREDICTIVO:
Modelos de supervivencia para predecir la probabilidad de fallo a lo largo del tiempo
Los tres enfoques anteriores se centran en la predicción, dándole suficiente información para aplicar el mantenimiento antes del fallo. Sin embargo, si lo que le interesa es el propio proceso de degradación y la probabilidad de fallo resultante, esta última estrategia es la más adecuada para usted.
PREGUNTA: Dado un conjunto de características, ¿cómo evoluciona el riesgo de impago a lo largo del tiempo?
CARACTERÍSTICAS DE LOS DATOS: Datos estáticos disponibles, información sobre el tiempo de avería notificado de cada máquina o la fecha registrada en la que una máquina determinada dejó de ser observable en caso de avería.
Un modelo de supervivencia estima la probabilidad de fallo de un determinado tipo de máquina en función de características estáticas, y también es útil para analizar el impacto de determinadas características en la vida útil. Por tanto, proporciona estimaciones para un grupo de máquinas con características similares. Por tanto, para una máquina concreta objeto de estudio, no tiene en cuenta su estado actual específico.
PARA CONCLUIR
¿Cuál es el enfoque más adecuado para un modelo de mantenimiento predictivo? Como ocurre con todos los demás problemas de la ciencia de datos, no se puede acertar a la primera. El consejo en este caso es empezar por comprender los tipos de fallos que se intentan modelizar, el tipo de resultados que se desea obtener con el modelo y el tipo de datos disponibles.
Una vez reunido todo esto con los consejos anteriores, espero que ahora sepa por dónde empezar.
¿Necesita la opinión de un experto?
Siga nuestras innovaciones en las redes sociales
Publicamos con frecuencia en las redes sociales (Linkedin, Twitter y Medio) nuestras innovaciones y las nuevas funciones de nuestras soluciones de gestión industrial.
También estaremos encantados de compartir con usted las últimas tendencias en gestión industrial 4.0 a través de contenidos de alta calidad que podrá compartir con otras personas.


