Apprentissage automatique pour la maintenance prédictive: par où commencer?
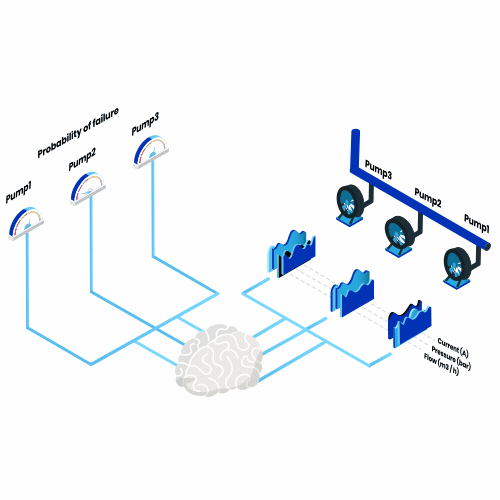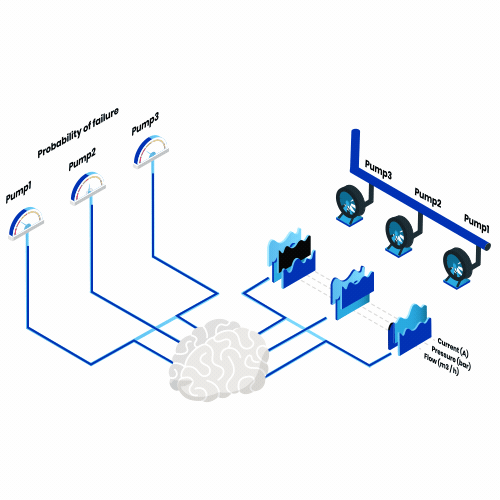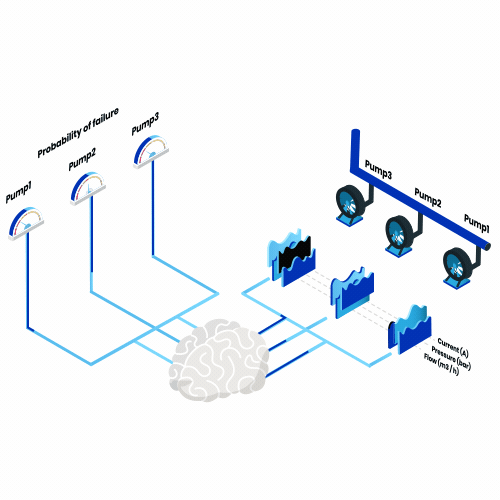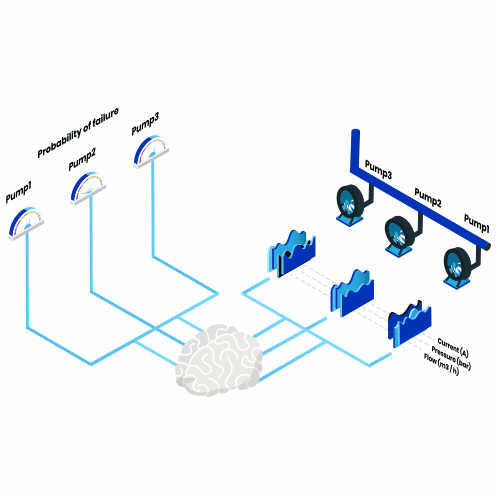
C’est quoi la maintenance prédictive? Pensez à toutes les machines que vous utilisez pendant une année, toutes, d’un grille-pain tous les matins à un avion toutes les vacances d’été. Imaginez maintenant que, désormais, l’un d’entre eux tomberait en panne chaque jour. Quel impact cela aurait-il?
En effet, nous sommes entourés de machines qui nous facilitent la vie, mais nous en dépendons également de plus en plus. Par conséquent, la qualité d’une machine ne dépend pas seulement de son utilité et de son efficacité, mais aussi de sa fiabilité. Et avec la fiabilité vient la maintenance.
Lorsque l’impact d’une panne ne peut être toléré, comme un moteur d’avion défectueux par exemple; la machine est soumise à une maintenance préventive, qui implique une inspection et une réparation périodiques; souvent programmées en fonction du temps de service.
Donc, l’objectif de la maintenance prédictive c’est de répondre à cette question. Ainsi, nous cherchons à construire des modèles qui quantifient le risque de panne d’une machine à tout moment dans le temps et utilisent ces informations pour améliorer la planification de la maintenance.
Le succès des modèles de maintenance prédictive dépend de trois éléments principaux: disposer des bonnes données, définir le problème de manière appropriée et évaluer correctement les prévisions.
Dans cet article, nous développerons les deux premiers points et donnerons des informations sur la manière de choisir la technique de modélisation qui correspond le mieux à la question à laquelle vous essayez de répondre et aux données dont vous disposez.
LA COLLECTE DE DONNÉES
Premièrement, pour créer un modèle de défaillance, nous avons besoin de suffisamment de données historiques pour capturer des informations sur les événements conduisant à une défaillance.
En plus de cela, des information précieuses viennent des caractéristiques générales «statiques» du système; telles que les propriétés mécaniques, l’utilisation moyenne et les conditions de fonctionnement. Cependant, plus de données n’est pas toujours mieux. Lors de la collecte de données et pour prendre en charge un modèle de défaillance, il est important de faire un inventaire des éléments suivants:
À quoi ressemble le «processus de panne»? S'agit-il d'un processus de dégradation lente ou aiguë?
Quelles parties de la machine / du système pourraient être liées à chaque type de panne? Que peut-on mesurer sur chacun d'eux qui reflète leur état? À quelle fréquence et avec quelle précision ces mesures doivent-elles être effectuées?
Ainsi, la durée de vie des machines est généralement de l’ordre de quelques années; ce qui signifie que les données doivent être collectées pendant une période prolongée afin d’observer le système tout au long de son processus de dégradation.
Dans un scénario idéal, les Data Scientist seraient impliqués dans le plan de collecte de données pour s’assurer que les données recueillies sont adaptées au modèle à construire. Cependant, ce qui se passe le plus souvent dans la vie réelle, c’est que les données ont déjà été collectées avant l’arrivée du data scientist et qu’il / elle doit essayer de tirer le meilleur parti de ce qui est disponible.
Donc, en fonction des caractéristiques du système et des données disponibles; un bon cadrage du modèle à construire est essentiel: à quelle question voulons-nous que le modèle réponde et est-ce possible avec les données dont nous disposons?
LA DÉFINITION DU PROBLÈME
Lorsque vous réfléchissez à la manière de définir un modèle de maintenance prédictive, il est important de garder à l’esprit quelques questions:
- Quel type de sortie le modèle doit-il donner?
- Y a-t-il suffisamment de données historiques disponibles ou simplement des données statiques?
- Chaque événement enregistré est-il étiqueté; c’est-à-dire quelles mesures correspondent à un bon fonctionnement et lesquelles correspondent à une défaillance? Ou du moins, est-il connu quand chaque machine est tombée en panne (voire pas du tout)?
- Lorsque des événements étiquetés sont disponibles; quelle est la proportion du nombre d’événements de chaque type de panne et d’événements de bon fonctionnement?
- Combien de temps à l’avance le modèle doit-il être en mesure d’indiquer qu’une panne se produira?
- Quels sont les objectifs de performance pour lesquels le modèle doit être optimisé? Quelle est la conséquence de ne pas prédire une panne?
Ainsi, avec toutes ces informations à portée de main, nous pouvons maintenant décider quelle stratégie de modélisation correspond le mieux aux données disponibles et à la sortie souhaitée; ou au moins laquelle est le meilleur candidat pour commencer. Il existe plusieurs stratégies de modélisation pour la maintenance prédictive et nous en décrirons quatre en fonction de la question à laquelle elles visent à répondre et du type de données dont elles ont besoin:
- Modèles de régression pour prédire la durée de vie utile restante (RUL)
- Modèles de classification pour prédire les pannes dans une fenêtre de temps donnée
- Signaler un comportement anormal
- Modèles de survie pour la prédiction de la probabilité de défaillance dans le temps
STRATÉGIE 1 MAINTENANCE PRÉDICTIVE:
Modèles de régression pour prédire la durée de vie utile restante.
SORTIE: Combien de jours / cycles reste-t-il avant que le système ne tombe en panne?
CARACTÉRISTIQUES DES DONNÉES: Des données statiques et historiques sont disponibles, et chaque événement est étiqueté. Plusieurs événements de chaque type de panne sont présents dans le jeu de données.
HYPOTHÈSES / EXIGENCES DE BASE:
Sur la base des caractéristiques statiques du système et de son comportement actuel; le temps utile restant peut être prédit, ce qui implique que des données statiques et historiques sont nécessaires et que le processus de dégradation est régulier.
Un seul type de «chemin vers la défaillance» est modélisé: si plusieurs types de défaillance sont possibles et que le comportement du système précédant chacun d’entre eux diffère; un modèle dédié doit être créé pour chacun d’eux.
Des données étiquetées sont disponibles et des mesures ont été prises à différents moments de la durée de vie du système.
STRATÉGIE 2 MAINTENANCE PRÉDICTIVE:
Modèles de classification pour prédire une panne dans une fenêtre temporelle donnée
Créer un modèle capable de prédire très précisément les durées de vie peut être très difficile.
Dans la pratique cependant, il n’est généralement pas nécessaire de prédire la durée de vie avec précision. Souvent, l’équipe maintenance a seulement besoin de savoir si la machine sera bientôt en panne. Cela aboutit à la stratégie suivante:
QUESTION: Une machine tombera-t-elle en panne dans les N prochains jours / cycles?
CARACTÉRISTIQUES DES DONNÉES: Idem que pour la stratégie 1
HYPOTHÈSES / EXIGENCES DE BASE: Les hypothèses d’un modèle de classification sont très similaires à celles des modèles de régression. Ils diffèrent principalement sur les ponts suivants:
- Puisque nous définissons une défaillance dans une fenêtre temporelle au lieu d’une heure exacte; l’exigence de régularité du processus de dégradation est relâchée.
- Les modèles de classification peuvent traiter plusieurs types de défaillance, à condition qu’ils soient présentés comme un problème multi-classes, par exemple: classe = 0 correspondant à aucune défaillance dans les n jours suivants, classe = 1 pour la défaillance de type 1 dans les n jours suivants , class = 2 pour une panne sévère dans les n prochains jours et ainsi de suite.
- Des données étiquetées sont disponibles et il y a «suffisamment» de cas de chaque type de panne pour entraîner et évaluer le modèle.
En général, les modèles de régression et de classification modélisent la relation entre les caractéristiques et le chemin de dégradation du système. Cela signifie que si le modèle est appliqué à un système qui présente un type de défaillance différent non présent dans les données d’apprentissage, le modèle ne parviendra pas à le prédire.
STRATÉGIE 3 MAINTENANCE PRÉDICTIVE:
Signaler un comportement anormal
Les deux stratégies précédentes nécessitent de nombreux exemples à la fois de comportements normaux (dont nous avons souvent beaucoup) et d’exemples de pannes.
Cependant, combien d’avions laisserez-vous s’écraser pour collecter des données? Si vous avez des systèmes critiques, dans lesquels les réparations aiguës sont difficiles; il n’y a souvent que des exemples de pannes limités, voire aucun. Dans ce cas, une stratégie différente est nécessaire:
QUESTION: Le comportement affiché est-il normal?
CARACTÉRISTIQUES DES DONNÉES: Des données statiques et historiques sont disponibles, mais soit les étiquettes sont inconnues; soit trop peu d’événements de défaillance ont été observés ou il y a trop de types de défaillance
HYPOTHÈSES / EXIGENCES DE BASE: Il est possible de définir ce qu’est un comportement normal et la différence entre le comportement actuel et le comportement «normal» est liée à une dégradation conduisant à une défaillance.
La généralité d’un modèle de détection d’anomalies est à la fois son plus grand avantage et son plus grand écueil: le modèle devrait être capable de signaler tous les types de défaillance; même s’il n’en a pas eu de connaissance préalable. Cependant, un comportement anormal ne conduit pas nécessairement à une panne. Et si c’est le cas, le modèle ne donne pas d’informations sur la durée pendant laquelle il devrait se produire.
L’évaluation d’un modèle de détection d’anomalies est également difficile en raison du manque de données étiquetées. Si au moins certaines données étiquetées de pannes, sont disponibles, elles peuvent et doivent être utilisées pour évaluer l’algorithme. Lorsqu’aucune donnée étiquetée n’est disponible, le modèle est généralement mis à disposition et les experts du domaine fournissent des commentaires sur la qualité de sa capacité de signalisation des anomalies.
STRATÉGIE 4 MAINTENANCE PRÉDICTIVE:
Modèles de survie pour la prédiction de la probabilité de défaillance dans le temps
Les trois approches précédentes se concentrent sur la prédiction, vous donnant suffisamment d’informations pour appliquer la maintenance avant la panne. Si toutefois vous êtes intéressé par le processus de dégradation lui-même et la probabilité de défaillance qui en résulte, cette dernière stratégie vous convient le mieux.
QUESTION: Compte tenu d’un ensemble de caractéristiques, comment le risque de défaillance évolue-t-il dans le temps?
CARACTÉRISTIQUES DES DONNÉES: Données statiques disponibles, informations sur l’heure de panne signalée de chaque machine ou date enregistrée à laquelle une machine donnée est devenue inobservable en cas de panne.
Un modèle de survie estime la probabilité de défaillance pour un type donné de machine en fonction des caractéristiques statiques et est également utile pour analyser l’impact de certaines caractéristiques sur la durée de vie. Il fournit donc des estimations pour un groupe de machines de caractéristiques similaires. Par conséquent, pour une machine spécifique à l’étude, il ne prend pas en compte son état actuel spécifique.
POUR CONCLURE
Quelle est l’approche la plus appropriée pour un modèle de maintenance prédictive? Comme pour tous les autres problèmes de Data Science, rien n’est gagné du premier coup! Le conseil ici est de commencer par comprendre les types de défaillance que vous essayez de modéliser, le type de sortie que vous souhaitez que le modèle délivre et le type de données disponibles.
Après avoir mis tout cela ensemble avec les conseils donnés ci-dessus, j’espère que vous savez maintenant par où commencer!
Vous avez besoin d'un avis d'expert ?
Suivez nos innovations sur les réseaux sociaux
Nous publions fréquemment sur les réseaux sociaux (Linkedin, Twitter et Medium) nos innovations et les nouvelles fonctionnalités de nos solutions de gestion industrielle.
De même, nous serions heureux de vous faire profiter des dernière tendance de la gestion industrielle 4.0 au travers de contenu d’excellente qualité que vous pourriez repartager.


