Maschinelles Lernen für die vorausschauende Wartung: Wo soll ich anfangen?
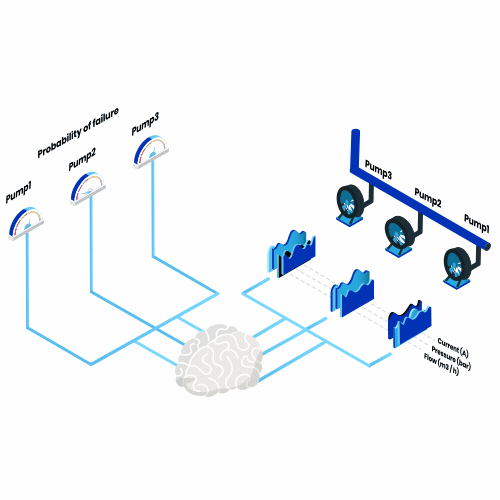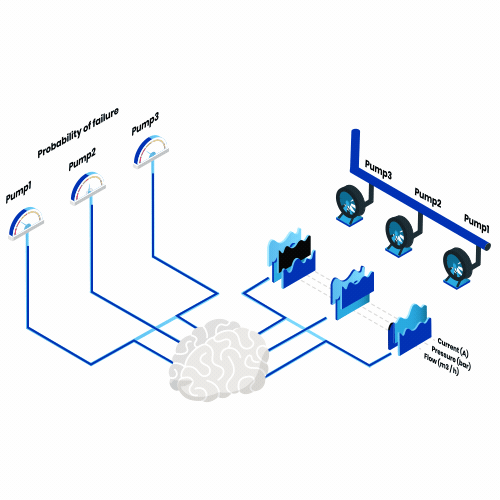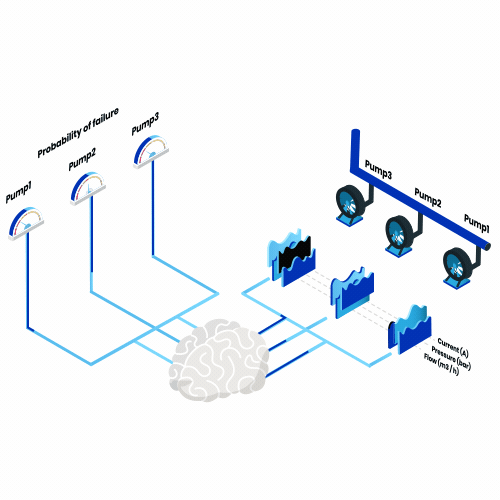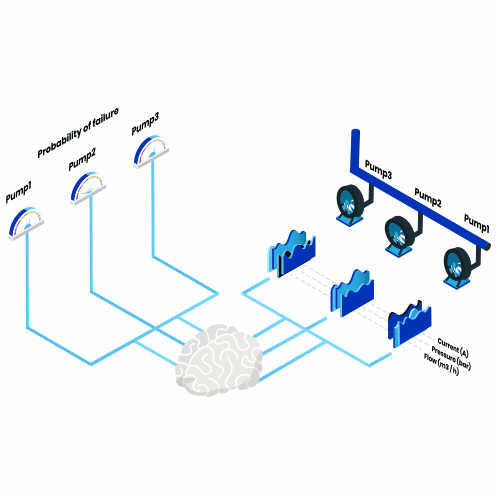
Was ist vorausschauende Wartung? Denken Sie an all die Maschinen, die Sie im Laufe eines Jahres benutzen, vom morgendlichen Toaster bis zum Flugzeug in den Sommerferien. Stellen Sie sich nun vor, dass von nun an jeden Tag eine dieser Maschinen ausfallen würde. Wie würde sich das auswirken?
Tatsächlich sind wir von Maschinen umgeben, die uns das Leben erleichtern, aber wir sind auch zunehmend von ihnen abhängig. Daher hängt die Qualität einer Maschine nicht nur von ihrem Nutzen und ihrer Effizienz ab, sondern auch von ihrer Zuverlässigkeit. Und mit der Zuverlässigkeit kommt auch die Wartung.
Wenn die Auswirkungen eines Ausfalls nicht toleriert werden können, wie z. B. bei einem defekten Flugzeugtriebwerk, wird die Maschine einer vorbeugenden Wartung unterzogen, die eine regelmäßige Inspektion und Reparatur beinhaltet.
Das Ziel der vorausschauenden Wartung ist es also, diese Frage zu beantworten. Daher versuchen wir, Modelle zu erstellen, die das Risiko eines Maschinenausfalls zu jedem beliebigen Zeitpunkt quantifizieren und diese Informationen zur Verbesserung der Wartungsplanung nutzen.
Der Erfolg von Modellen zur vorausschauenden Wartung hängt von drei Hauptelementen ab: den richtigen Daten, einer angemessenen Definition des Problems und einer korrekten Bewertung der Vorhersagen.
In diesem Artikel werden wir die ersten beiden Punkte ausführen und Informationen dazu geben, wie Sie die Modellierungstechnik auswählen können, die am besten zu der Frage passt, die Sie zu beantworten versuchen, und zu den Daten, die Ihnen zur Verfügung stehen.
DAS SAMMELN VON DATEN
Erstens: Um ein Ausfallmodell zu erstellen, benötigen wir ausreichend historische Daten, um Informationen über Ereignisse, die zu einem Ausfall führen, zu erfassen.
Darüber hinaus ergeben sich wertvolle Informationen aus den allgemeinen "statischen" Merkmalen des Systems, wie z. B. den mechanischen Eigenschaften, der durchschnittlichen Nutzung und den Betriebsbedingungen. Mehr Daten sind jedoch nicht immer besser. Bei der Sammlung von Daten und der Unterstützung eines Ausfallmodells ist es wichtig, eine Bestandsaufnahme der folgenden Elemente vorzunehmen:
Wie sieht der "Pannenprozess" aus? Handelt es sich um einen langsamen oder akuten Verfallsprozess?
Welche Teile der Maschine/des Systems könnten mit jeder Art von Störung in Verbindung stehen? Was kann man an jedem Teil messen, um den Zustand der Maschine/des Systems widerzuspiegeln? Wie oft und wie genau sollten diese Messungen durchgeführt werden?
Dies bedeutet, dass die Daten über einen längeren Zeitraum gesammelt werden müssen, um das System während des gesamten Verfallsprozesses zu beobachten.
In einem idealen Szenario wäre der Data Scientist in den Datenerhebungsplan eingebunden, um sicherzustellen, dass die gesammelten Daten für das zu erstellende Modell geeignet sind. Im wirklichen Leben ist es jedoch meist so, dass die Daten bereits vor der Ankunft des Data Scientists gesammelt wurden und er / sie versuchen muss, das Beste aus dem zu machen, was verfügbar ist.
Welche Frage soll das Modell beantworten, und ist das mit den verfügbaren Daten möglich?
DIE DEFINITION DES PROBLEMS
Wenn Sie darüber nachdenken, wie Sie ein Modell für vorausschauende Wartung definieren können, sollten Sie einige Fragen im Hinterkopf behalten:
- Welche Art von Ausgabe soll die Vorlage liefern?
- Gibt es genügend historische Daten oder nur statische Daten?
- Wird jedes aufgezeichnete Ereignis beschriftet, d. h. welche Messungen entsprechen einem guten Funktionieren und welche einem Ausfall? Oder ist zumindest bekannt, wann welche Maschine ausgefallen ist (oder gar nicht)?
- Wenn gekennzeichnete Ereignisse verfügbar sind: Wie hoch ist das Verhältnis der Anzahl von Ereignissen jeder Art von Ausfall zu Ereignissen mit einwandfreiem Betrieb?
- Wie lange im Voraus muss das Modell anzeigen können, dass ein Fehler auftritt?
- Für welche Leistungsziele muss das Modell optimiert werden? Was ist die Konsequenz, wenn ein Ausfall nicht vorhergesagt wird?
Mit all diesen Informationen zur Hand können wir nun entscheiden, welche Modellierungsstrategie am besten zu den verfügbaren Daten und der gewünschten Ausgabe passt - oder zumindest, welche der beste Kandidat für den Anfang ist. Es gibt mehrere Modellierungsstrategien für die vorausschauende Wartung, und wir werden vier davon beschreiben, je nachdem, welche Frage sie beantworten sollen und welche Art von Daten sie benötigen:
- Regressionsmodelle zur Vorhersage der Restnutzungsdauer (RUL)
- Klassifikationsmodelle zur Vorhersage von Ausfällen in einem bestimmten Zeitfenster
- Abnormales Verhalten melden
- Überlebensmodelle für die Vorhersage der Ausfallwahrscheinlichkeit im Zeitverlauf
STRATEGIE 1 VORAUSSCHAUENDE WARTUNG:
Regressionsmodelle zur Vorhersage der verbleibenden Nutzungsdauer.
AUSGANG: Wie viele Tage/Zyklen bleiben, bevor das System ausfällt?
DATENMERKMALE: Es sind statische und historische Daten verfügbar, und jedes Ereignis ist mit einem Tag versehen. Der Datensatz enthält mehrere Ereignisse jeder Art von Stromausfall.
GRUNDLEGENDE ANNAHMEN / ANFORDERUNGEN:
Auf der Grundlage der statischen Eigenschaften des Systems und seines aktuellen Verhaltens kann die verbleibende Nutzungszeit vorhergesagt werden. Dies setzt voraus, dass statische und historische Daten benötigt werden und dass der Abbauprozess regelmäßig erfolgt.
Nur eine Art von "Pfad zum Ausfall" wird modelliert: Wenn mehrere Ausfallarten möglich sind und sich das Systemverhalten vor jeder von ihnen unterscheidet, muss für jede von ihnen ein eigenes Modell erstellt werden.
Es liegen gekennzeichnete Daten vor und es wurden Messungen zu verschiedenen Zeitpunkten während der Lebensdauer des Systems durchgeführt.
STRATEGIE 2 VORAUSSCHAUENDE WARTUNG:
Klassifikationsmodelle zur Vorhersage eines Ausfalls in einem bestimmten Zeitfenster
Ein Modell zu erstellen, das die Lebensdauer sehr genau vorhersagen kann, kann sehr schwierig sein.
In der Praxis ist es jedoch meist nicht notwendig, die Lebensdauer genau vorherzusagen. Oft muss das Wartungsteam nur wissen, ob die Maschine bald ausfallen wird. Dies führt zu der folgenden Strategie:
FRAGE: Wird eine Maschine in den nächsten N Tagen / Zyklen ausfallen?
DATENMERKMALE: Wie bei Strategie 1.
HYPOTHESEN / GRUNDLEGENDE ANFORDERUNGEN: Die Annahmen eines Klassifikationsmodells sind denen von Regressionsmodellen sehr ähnlich. Sie unterscheiden sich hauptsächlich in folgenden Punkten
- Da wir einen Ausfall innerhalb eines Zeitfensters statt einer genauen Uhrzeit definieren, wird die Anforderung an die Regelmäßigkeit des Abbauprozesses gelockert.
- Klassifikationsmodelle können mehrere Arten von Ausfällen behandeln, vorausgesetzt, sie werden als ein Problem mit mehreren Klassen dargestellt, z. B. Klasse = 0 entspricht keinem Ausfall in den nächsten n Tagen, Klasse = 1 steht für einen Ausfall des Typs 1 in den nächsten n Tagen, Klasse = 2 für einen schweren Ausfall in den nächsten n Tagen und so weiter.
- Es sind beschriftete Daten verfügbar und es gibt "genügend" Fälle jeder Art von Ausfall, um das Modell zu trainieren und zu bewerten.
Im Allgemeinen modellieren Regressions- und Klassifikationsmodelle die Beziehung zwischen den Merkmalen und dem Schädigungspfad des Systems. Das heißt, wenn das Modell auf ein System angewendet wird, das einen anderen Ausfalltyp aufweist, der nicht in den Trainingsdaten vorhanden ist, wird das Modell nicht in der Lage sein, diesen vorherzusagen.
STRATEGIE 3 VORAUSSCHAUENDE WARTUNG:
Abnormales Verhalten melden
Die beiden vorherigen Strategien erfordern viele Beispiele sowohl für normales Verhalten (von dem wir oft viele haben) als auch für Fehlerbeispiele.
Aber wie viele Flugzeuge lassen Sie abstürzen, um Daten zu sammeln? Wenn Sie kritische Systeme haben, bei denen akute Reparaturen schwierig sind, gibt es oft nur wenige oder gar keine Beispiele für Ausfälle. In diesem Fall ist eine andere Strategie erforderlich:
FRAGE: Ist das gezeigte Verhalten normal?
DATENMERKMALE: Statische und historische Daten sind verfügbar, aber entweder sind die Kennzeichnungen unbekannt, oder es wurden zu wenige Ausfallereignisse beobachtet oder es gibt zu viele Ausfallarten
BASISHYPOTHESEN / ANFORDERUNGEN: Es ist möglich, normales Verhalten zu definieren, und der Unterschied zwischen dem aktuellen Verhalten und dem "normalen" Verhalten ist mit einer Verschlechterung verbunden, die zu einem Ausfall führt.
Die Allgemeingültigkeit eines Anomalieerkennungsmodells ist sowohl sein größter Vorteil als auch sein größter Nachteil: Das Modell sollte in der Lage sein, alle Arten von Fehlern zu melden, selbst wenn es keine vorherige Kenntnis davon hat. Abnormales Verhalten muss jedoch nicht zwangsläufig zu einem Ausfall führen. Und wenn dies der Fall ist, gibt das Modell keine Auskunft darüber, wie lange es dauern sollte.
Die Bewertung eines Modells zur Fehlererkennung ist auch deshalb schwierig, weil es an gekennzeichneten Daten mangelt. Wenn zumindest einige gelabelte Daten von Ausfällen verfügbar sind, können und sollten sie zur Bewertung des Algorithmus verwendet werden. Wenn keine gelabelten Daten verfügbar sind, wird das Modell in der Regel zur Verfügung gestellt und Domänenexperten geben Feedback über die Qualität seiner Fähigkeit, Anomalien zu melden.
STRATEGIE 4 VORAUSSCHAUENDE WARTUNG:
Überlebensmodelle für die Vorhersage der Ausfallwahrscheinlichkeit im Zeitverlauf
Die drei vorherigen Ansätze konzentrieren sich auf die Vorhersage und geben Ihnen genügend Informationen, um die Wartung vor dem Ausfall anzuwenden. Wenn Sie sich jedoch für den Abbauprozess selbst und die daraus resultierende Ausfallwahrscheinlichkeit interessieren, ist die letzte Strategie für Sie am besten geeignet.
FRAGE: Wie verändert sich das Ausfallrisiko unter Berücksichtigung einer Reihe von Merkmalen im Laufe der Zeit?
DATENMERKMALE: Verfügbare statische Daten, Informationen über den Zeitpunkt des gemeldeten Ausfalls jeder Maschine oder das aufgezeichnete Datum, an dem eine bestimmte Maschine bei einem Ausfall unbeobachtbar wurde.
Ein Überlebensmodell schätzt die Ausfallwahrscheinlichkeit für einen bestimmten Maschinentyp in Abhängigkeit von statischen Merkmalen und ist auch nützlich, um die Auswirkungen bestimmter Merkmale auf die Lebensdauer zu analysieren. Es liefert daher Schätzungen für eine Gruppe von Maschinen mit ähnlichen Eigenschaften. Für eine bestimmte zu untersuchende Maschine berücksichtigt er daher nicht ihren spezifischen aktuellen Zustand.
ZUM ABSCHLUSS
Welcher Ansatz ist für ein Modell zur vorausschauenden Wartung am besten geeignet? Wie bei allen anderen Problemen der Data Science gilt auch hier: Nichts ist beim ersten Versuch gewonnen! Der Ratschlag lautet hier, dass Sie zunächst die Arten von Fehlern, die Sie zu modellieren versuchen, die Art der Ausgabe, die das Modell liefern soll, und die Art der verfügbaren Daten verstehen sollten.
Ich hoffe, Sie wissen jetzt, wo Sie anfangen sollen.
Brauchen Sie eine Expertenmeinung?
Verfolgen Sie unsere Innovationen in sozialen Netzwerken
Wir veröffentlichen häufig in sozialen Netzwerken (Linkedin, Twitter und Medium) unsere Innovationen und die neuen Funktionen unserer Lösungen für das Industriemanagement.
Außerdem würden wir uns freuen, wenn wir Ihnen die neuesten Trends im Bereich Industrie 4.0 durch qualitativ hochwertige Inhalte, die Sie weiterverbreiten können, näher bringen könnten.


